磁盘I/O那些事
計(jì)算機(jī)硬件性能在過(guò)去十年間的發(fā)展普遍遵循摩爾定律,通用計(jì)算機(jī)的CPU主頻早已超過(guò)3GHz,內(nèi)存也進(jìn)入了普及DDR4的時(shí)代。然而傳統(tǒng)硬盤(pán)雖然在存儲(chǔ)容量上增長(zhǎng)迅速,但是在讀寫(xiě)性能上并無(wú)明顯提升,同時(shí)SSD硬盤(pán)價(jià)格高昂,不能在短時(shí)間內(nèi)完全替代傳統(tǒng)硬盤(pán)。傳統(tǒng)磁盤(pán)的I/O讀寫(xiě)速度成為了計(jì)算機(jī)系統(tǒng)性能提高的瓶頸,制約了計(jì)算機(jī)整體性能的發(fā)展。
硬盤(pán)性能的制約因素是什么?如何根據(jù)磁盤(pán)I/O特性來(lái)進(jìn)行系統(tǒng)設(shè)計(jì)?針對(duì)這些問(wèn)題,本文將介紹硬盤(pán)的物理結(jié)構(gòu)和性能指標(biāo),以及操作系統(tǒng)針對(duì)磁盤(pán)性能所做的優(yōu)化,最后討論下基于磁盤(pán)I/O特性設(shè)計(jì)的技巧。
硬盤(pán)內(nèi)部主要部件為磁盤(pán)盤(pán)片、傳動(dòng)手臂、讀寫(xiě)磁頭和主軸馬達(dá)。實(shí)際數(shù)據(jù)都是寫(xiě)在盤(pán)片上,讀寫(xiě)主要是通過(guò)傳動(dòng)手臂上的讀寫(xiě)磁頭來(lái)完成。實(shí)際運(yùn)行時(shí),主軸讓磁盤(pán)盤(pán)片轉(zhuǎn)動(dòng),然后傳動(dòng)手臂可伸展讓讀取頭在盤(pán)片上進(jìn)行讀寫(xiě)操作。磁盤(pán)物理結(jié)構(gòu)如下圖所示:

由于單一盤(pán)片容量有限,一般硬盤(pán)都有兩張以上的盤(pán)片,每個(gè)盤(pán)片有兩面,都可記錄信息,所以一張盤(pán)片對(duì)應(yīng)著兩個(gè)磁頭。盤(pán)片被分為許多扇形的區(qū)域,每個(gè)區(qū)域叫一個(gè)扇區(qū),硬盤(pán)中每個(gè)扇區(qū)的大小固定為512字節(jié)。盤(pán)片表面上以盤(pán)片中心為圓心,不同半徑的同心圓稱(chēng)為磁道,不同盤(pán)片相同半徑的磁道所組成的圓柱稱(chēng)為柱面。磁道與柱面都是表示不同半徑的圓,在許多場(chǎng)合,磁道和柱面可以互換使用。磁盤(pán)盤(pán)片垂直視角如下圖所示:
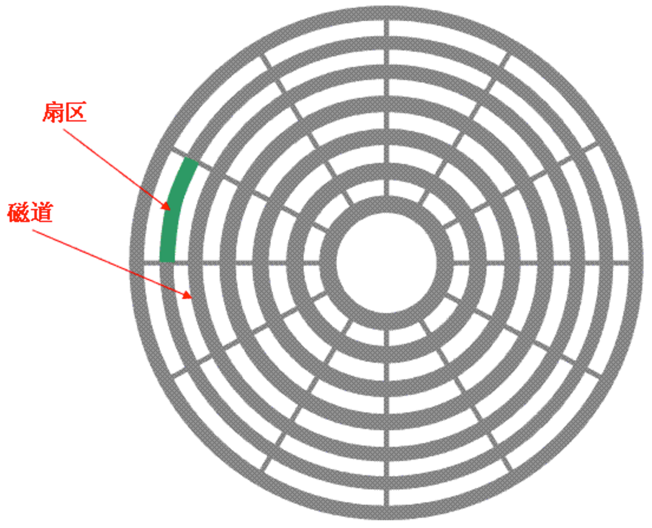
早期的硬盤(pán)每磁道扇區(qū)數(shù)相同,此時(shí)由磁盤(pán)基本參數(shù)可以計(jì)算出硬盤(pán)的容量:存儲(chǔ)容量=磁頭數(shù)*磁道(柱面)數(shù)*每道扇區(qū)數(shù)*每扇區(qū)字節(jié)數(shù)。由于每磁道扇區(qū)數(shù)相同,外圈磁道半徑大,里圈磁道半徑小,外圈和里圈扇區(qū)面積自然會(huì)不一樣。同時(shí),為了更好的讀取數(shù)據(jù),即使外圈扇區(qū)面積再大也只能和內(nèi)圈扇區(qū)一樣存放相同的字節(jié)數(shù)(512字節(jié))。這樣一來(lái),外圈的記錄密度就要比內(nèi)圈小,會(huì)浪費(fèi)大量的存儲(chǔ)空間。
如今的硬盤(pán)都使用ZBR(Zoned Bit Recording,區(qū)位記錄)技術(shù),盤(pán)片表面由里向外劃分為數(shù)個(gè)區(qū)域,不同區(qū)域的磁道扇區(qū)數(shù)目不同,同一區(qū)域內(nèi)各磁道扇區(qū)數(shù)相同,盤(pán)片外圈區(qū)域磁道長(zhǎng)扇區(qū)數(shù)目較多,內(nèi)圈區(qū)域磁道短扇區(qū)數(shù)目較少,大體實(shí)現(xiàn)了等密度,從而獲得了更多的存儲(chǔ)空間。此時(shí),由于每磁道扇區(qū)數(shù)各不相同,所以傳統(tǒng)的容量計(jì)算公式就不再適用。實(shí)際上如今的硬盤(pán)大多使用LBA(Logical Block Addressing)邏輯塊尋址模式,知道LBA后即可計(jì)算出硬盤(pán)容量。
影響磁盤(pán)的關(guān)鍵因素是磁盤(pán)服務(wù)時(shí)間,即磁盤(pán)完成一個(gè)I/O請(qǐng)求所花費(fèi)的時(shí)間,它由尋道時(shí)間、旋轉(zhuǎn)延遲和數(shù)據(jù)傳輸時(shí)間三部分構(gòu)成。
1. 尋道時(shí)間
Tseek是指將讀寫(xiě)磁頭移動(dòng)至正確的磁道上所需要的時(shí)間。尋道時(shí)間越短,I/O操作越快,目前磁盤(pán)的平均尋道時(shí)間一般在3-15ms。
2. 旋轉(zhuǎn)延遲
Trotation是指盤(pán)片旋轉(zhuǎn)將請(qǐng)求數(shù)據(jù)所在的扇區(qū)移動(dòng)到讀寫(xiě)磁盤(pán)下方所需要的時(shí)間。旋轉(zhuǎn)延遲取決于磁盤(pán)轉(zhuǎn)速,通常用磁盤(pán)旋轉(zhuǎn)一周所需時(shí)間的1/2表示。比如:7200rpm的磁盤(pán)平均旋轉(zhuǎn)延遲大約為60*1000/7200/2 = 4.17ms,而轉(zhuǎn)速為15000rpm的磁盤(pán)其平均旋轉(zhuǎn)延遲為2ms。
3. 數(shù)據(jù)傳輸時(shí)間
Ttransfer是指完成傳輸所請(qǐng)求的數(shù)據(jù)所需要的時(shí)間,它取決于數(shù)據(jù)傳輸率,其值等于數(shù)據(jù)大小除以數(shù)據(jù)傳輸率。目前IDE/ATA能達(dá)到133MB/s,SATA II可達(dá)到300MB/s的接口數(shù)據(jù)傳輸率,數(shù)據(jù)傳輸時(shí)間通常遠(yuǎn)小于前兩部分消耗時(shí)間。簡(jiǎn)單計(jì)算時(shí)可忽略。
機(jī)械硬盤(pán)的連續(xù)讀寫(xiě)性能很好,但隨機(jī)讀寫(xiě)性能很差,這主要是因?yàn)榇蓬^移動(dòng)到正確的磁道上需要時(shí)間,隨機(jī)讀寫(xiě)時(shí),磁頭需要不停的移動(dòng),時(shí)間都浪費(fèi)在了磁頭尋址上,所以性能不高。衡量磁盤(pán)的重要主要指標(biāo)是IOPS和吞吐量。
1. IOPS
IOPS(Input/Output Per Second)即每秒的輸入輸出量(或讀寫(xiě)次數(shù)),即指每秒內(nèi)系統(tǒng)能處理的I/O請(qǐng)求數(shù)量。隨機(jī)讀寫(xiě)頻繁的應(yīng)用,如小文件存儲(chǔ)等,關(guān)注隨機(jī)讀寫(xiě)性能,IOPS是關(guān)鍵衡量指標(biāo)。可以推算出磁盤(pán)的IOPS = 1000ms / (Tseek + Trotation + Transfer),如果忽略數(shù)據(jù)傳輸時(shí)間,理論上可以計(jì)算出隨機(jī)讀寫(xiě)最大的IOPS。常見(jiàn)磁盤(pán)的隨機(jī)讀寫(xiě)最大IOPS為: - 7200rpm的磁盤(pán) IOPS = 76 IOPS - 10000rpm的磁盤(pán)IOPS = 111 IOPS - 15000rpm的磁盤(pán)IOPS = 166 IOPS
2. 吞吐量
吞吐量(Throughput),指單位時(shí)間內(nèi)可以成功傳輸?shù)臄?shù)據(jù)數(shù)量。順序讀寫(xiě)頻繁的應(yīng)用,如視頻點(diǎn)播,關(guān)注連續(xù)讀寫(xiě)性能、數(shù)據(jù)吞吐量是關(guān)鍵衡量指標(biāo)。它主要取決于磁盤(pán)陣列的架構(gòu),通道的大小以及磁盤(pán)的個(gè)數(shù)。不同的磁盤(pán)陣列存在不同的架構(gòu),但他們都有自己的內(nèi)部帶寬,一般情況下,內(nèi)部帶寬都設(shè)計(jì)足夠充足,不會(huì)存在瓶頸。磁盤(pán)陣列與服務(wù)器之間的數(shù)據(jù)通道對(duì)吞吐量影響很大,比如一個(gè)2Gbps的光纖通道,其所能支撐的最大流量?jī)H為250MB/s。最后,當(dāng)前面的瓶頸都不再存在時(shí),硬盤(pán)越多的情況下吞吐量越大。
雖然15000rpm的磁盤(pán)計(jì)算出的理論最大IOPS僅為166,但在實(shí)際運(yùn)行環(huán)境中,實(shí)際磁盤(pán)的IOPS往往能夠突破200甚至更高。這其實(shí)就是在系統(tǒng)調(diào)用過(guò)程中,操作系統(tǒng)進(jìn)行了一系列的優(yōu)化。
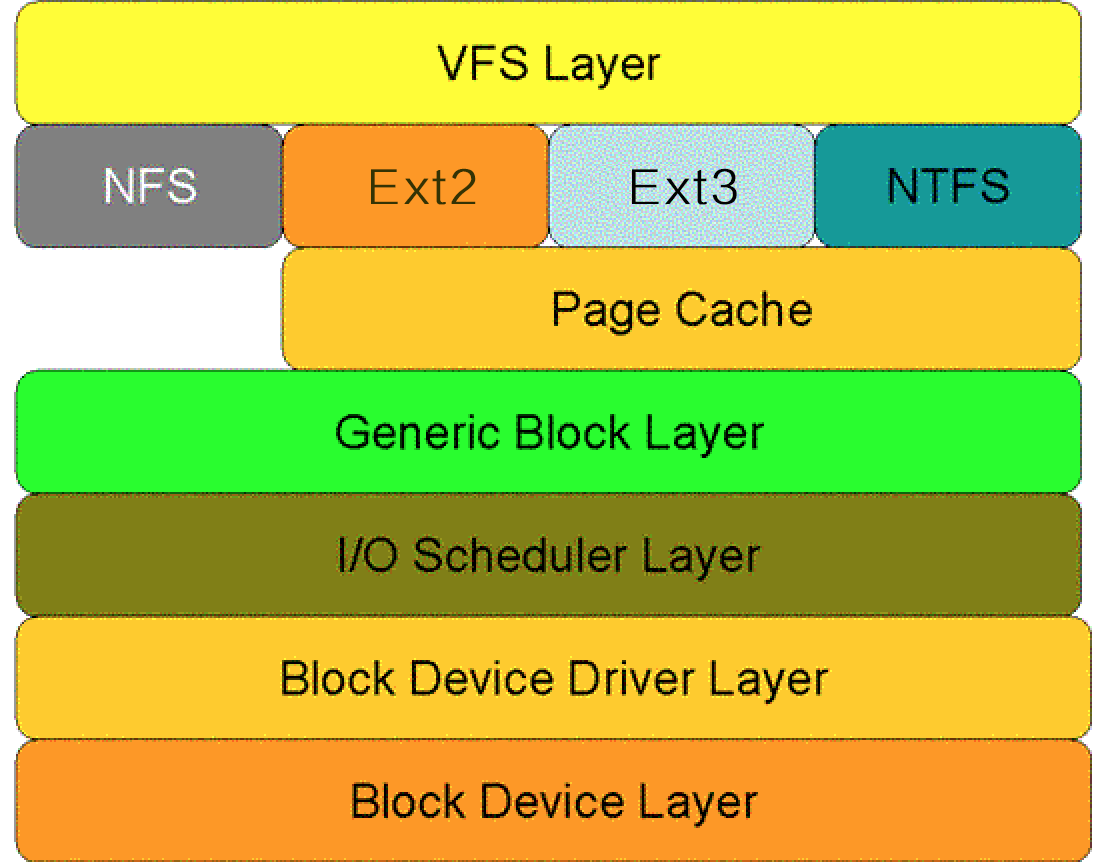
那么操作系統(tǒng)是如何操作硬盤(pán)的呢?類(lèi)似于網(wǎng)絡(luò)的分層結(jié)構(gòu),下圖顯示了Linux系統(tǒng)中對(duì)于磁盤(pán)的一次讀請(qǐng)求在核心空間中所要經(jīng)歷的層次模型。從圖中看出:對(duì)于磁盤(pán)的一次讀請(qǐng)求,首先經(jīng)過(guò)虛擬文件系統(tǒng)層(VFS Layer),其次是具體的文件系統(tǒng)層(例如Ext2),接下來(lái)是Cache層(Page Cache Layer)、通用塊層(Generic Block Layer)、I/O調(diào)度層(I/O Scheduler Layer)、塊設(shè)備驅(qū)動(dòng)層(Block Device Driver Layer),最后是物理塊設(shè)備層(Block Device Layer)。
虛擬文件系統(tǒng)層(VFS Layer)
VFS(Virtual File System)虛擬文件系統(tǒng)是一種軟件機(jī)制,更確切的說(shuō)扮演著文件系統(tǒng)管理者的角色,與它相關(guān)的數(shù)據(jù)結(jié)構(gòu)只存在于物理內(nèi)存當(dāng)中。它的作用是:屏蔽下層具體文件系統(tǒng)操作的差異,為上層的操作提供一個(gè)統(tǒng)一的接口。正是因?yàn)橛辛诉@個(gè)層次,Linux中允許眾多不同的文件系統(tǒng)共存并且對(duì)文件的操作可以跨文件系統(tǒng)而執(zhí)行。
VFS中包含著向物理文件系統(tǒng)轉(zhuǎn)換的一系列數(shù)據(jù)結(jié)構(gòu),如VFS超級(jí)塊、VFS的Inode、各種操作函數(shù)的轉(zhuǎn)換入口等。Linux中VFS依靠四個(gè)主要的數(shù)據(jù)結(jié)構(gòu)來(lái)描述其結(jié)構(gòu)信息,分別為超級(jí)塊、索引結(jié)點(diǎn)、目錄項(xiàng)和文件對(duì)象。
超級(jí)塊(Super Block):超級(jí)塊對(duì)象表示一個(gè)文件系統(tǒng)。它存儲(chǔ)一個(gè)已安裝的文件系統(tǒng)的控制信息,包括文件系統(tǒng)名稱(chēng)(比如Ext2)、文件系統(tǒng)的大小和狀態(tài)、塊設(shè)備的引用和元數(shù)據(jù)信息(比如空閑列表等等)。VFS超級(jí)塊存在于內(nèi)存中,它在文件系統(tǒng)安裝時(shí)建立,并且在文件系統(tǒng)卸載時(shí)自動(dòng)刪除。同時(shí)需要注意的是對(duì)于每個(gè)具體的文件系統(tǒng)來(lái)說(shuō),也有各自的超級(jí)塊,它們存放于磁盤(pán)。
索引結(jié)點(diǎn)(Inode):索引結(jié)點(diǎn)對(duì)象存儲(chǔ)了文件的相關(guān)元數(shù)據(jù)信息,例如:文件大小、設(shè)備標(biāo)識(shí)符、用戶(hù)標(biāo)識(shí)符、用戶(hù)組標(biāo)識(shí)符等等。Inode分為兩種:一種是VFS的Inode,一種是具體文件系統(tǒng)的Inode。前者在內(nèi)存中,后者在磁盤(pán)中。所以每次其實(shí)是將磁盤(pán)中的Inode調(diào)進(jìn)填充內(nèi)存中的Inode,這樣才是算使用了磁盤(pán)文件Inode。當(dāng)創(chuàng)建一個(gè)文件的時(shí)候,就給文件分配了一個(gè)Inode。一個(gè)Inode只對(duì)應(yīng)一個(gè)實(shí)際文件,一個(gè)文件也會(huì)只有一個(gè)Inode。
目錄項(xiàng)(Dentry):引入目錄項(xiàng)對(duì)象的概念主要是出于方便查找文件的目的。不同于前面的兩個(gè)對(duì)象,目錄項(xiàng)對(duì)象沒(méi)有對(duì)應(yīng)的磁盤(pán)數(shù)據(jù)結(jié)構(gòu),只存在于內(nèi)存中。一個(gè)路徑的各個(gè)組成部分,不管是目錄還是普通的文件,都是一個(gè)目錄項(xiàng)對(duì)象。如,在路徑/home/source/test.java中,目錄 /, home, source和文件 test.java都對(duì)應(yīng)一個(gè)目錄項(xiàng)對(duì)象。VFS在查找的時(shí)候,根據(jù)一層一層的目錄項(xiàng)找到對(duì)應(yīng)的每個(gè)目錄項(xiàng)的Inode,那么沿著目錄項(xiàng)進(jìn)行操作就可以找到最終的文件。
文件對(duì)象(File):文件對(duì)象描述的是進(jìn)程已經(jīng)打開(kāi)的文件。因?yàn)橐粋€(gè)文件可以被多個(gè)進(jìn)程打開(kāi),所以一個(gè)文件可以存在多個(gè)文件對(duì)象。一個(gè)文件對(duì)應(yīng)的文件對(duì)象可能不是惟一的,但是其對(duì)應(yīng)的索引節(jié)點(diǎn)和目錄項(xiàng)對(duì)象肯定是惟一的。
Ext2文件系統(tǒng)
VFS的下一層即是具體的文件系統(tǒng),本節(jié)簡(jiǎn)要介紹下Linux的Ext2文件系統(tǒng)。
一個(gè)文件系統(tǒng)一般使用塊設(shè)備上一個(gè)獨(dú)立的邏輯分區(qū)。對(duì)于Ext2文件系統(tǒng)來(lái)說(shuō),硬盤(pán)分區(qū)首先被劃分為一個(gè)個(gè)的Block,一個(gè)Ext2文件系統(tǒng)上的每個(gè)Block都是一樣大小的。但是不同Ext2文件系統(tǒng),Block大小可能不同,這是在創(chuàng)建Ext2系統(tǒng)決定的,一般為1k或者4k。由于Block數(shù)量很多,為了方便管理,Ext2將這些Block聚集在一起分為幾個(gè)大的塊組(Block Group),每個(gè)塊組包含的等量的物理塊,在塊組的數(shù)據(jù)塊中存儲(chǔ)文件或目錄。Ext2文件系統(tǒng)存儲(chǔ)結(jié)構(gòu)如下圖所示:
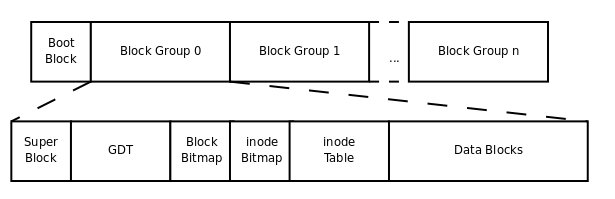
Ext2中的Super Block和Inode Table分別對(duì)應(yīng)VFS中的超級(jí)塊和索引結(jié)點(diǎn),存放在磁盤(pán)。每個(gè)塊組都有一個(gè)塊組描述符GDT(Group Descriptor Table),存儲(chǔ)一個(gè)塊組的描述信息,例如在這個(gè)塊組中從哪里開(kāi)始是Inode表,從哪里開(kāi)始是數(shù)據(jù)塊等等。Block Bitmap和Inode Bitmap分別表示Block和Inode是否空閑可用。Data Block數(shù)據(jù)塊是用來(lái)真正存儲(chǔ)文件內(nèi)容數(shù)據(jù)的地方,下面我們看一下具體的存儲(chǔ)規(guī)則。
在Ext2文件系統(tǒng)中所支持的Block大小有1K、2K、4K三種。在格式化時(shí)Block的大小就固定了,且每個(gè)Block都有編號(hào),方便Inode的記錄。每個(gè)Block內(nèi)最多只能夠放置一個(gè)文件的數(shù)據(jù),如果文件大于Block的大小,則一個(gè)文件會(huì)占用多個(gè)Block;如果文件小于Block,則該Block的剩余容量就不能夠再被使用了,即磁盤(pán)空間會(huì)浪費(fèi)。下面看看Inode和Block的對(duì)應(yīng)關(guān)系。
Inode要記錄的數(shù)據(jù)非常多,但大小僅為固定的128字節(jié),同時(shí)記錄一個(gè)Block號(hào)碼就需要4字節(jié),假設(shè)一個(gè)文件有400MB且每個(gè)Block為4K時(shí),那么至少也要十萬(wàn)筆Block號(hào)碼的記錄。Inode不可能有這么多的記錄信息,因此Ext2將Inode記錄Block號(hào)碼的區(qū)域定義為12個(gè)直接、一個(gè)間接、一個(gè)雙間接與一個(gè)三間接記錄區(qū)。Inode存儲(chǔ)結(jié)構(gòu)如下圖所示:
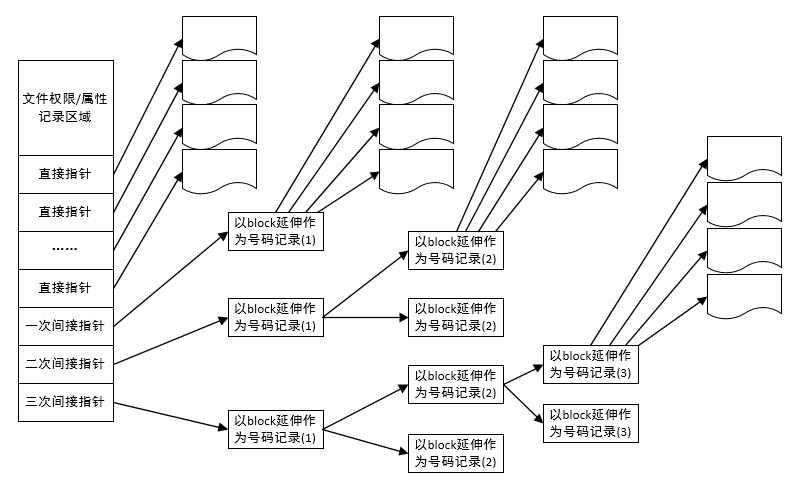
最左邊為Inode本身(128 bytes),里面有12個(gè)直接指向Block號(hào)碼的對(duì)照,這12筆記錄能夠直接取得Block號(hào)碼。至于所謂的間接就是再拿一個(gè)Block來(lái)當(dāng)作記錄Block號(hào)碼的記錄區(qū),如果文件太大時(shí),就會(huì)使用間接的Block來(lái)記錄編號(hào)。如上圖當(dāng)中間接只是拿一個(gè)Block來(lái)記錄額外的號(hào)碼而已。 同理,如果文件持續(xù)長(zhǎng)大,那么就會(huì)利用所謂的雙間接,第一個(gè)Block僅再指出下一個(gè)記錄編號(hào)的Block在哪里,實(shí)際記錄的在第二個(gè)Block當(dāng)中。依此類(lèi)推,三間接就是利用第三層Block來(lái)記錄編號(hào)。
Page Cache層
引入Cache層的目的是為了提高Linux操作系統(tǒng)對(duì)磁盤(pán)訪(fǎng)問(wèn)的性能。Cache層在內(nèi)存中緩存了磁盤(pán)上的部分?jǐn)?shù)據(jù)。當(dāng)數(shù)據(jù)的請(qǐng)求到達(dá)時(shí),如果在Cache中存在該數(shù)據(jù)且是最新的,則直接將數(shù)據(jù)傳遞給用戶(hù)程序,免除了對(duì)底層磁盤(pán)的操作,提高了性能。Cache層也正是磁盤(pán)IOPS為什么能突破200的主要原因之一。
在Linux的實(shí)現(xiàn)中,文件Cache分為兩個(gè)層面,一是Page Cache,另一個(gè)Buffer Cache,每一個(gè)Page Cache包含若干Buffer Cache。Page Cache主要用來(lái)作為文件系統(tǒng)上的文件數(shù)據(jù)的緩存來(lái)用,尤其是針對(duì)當(dāng)進(jìn)程對(duì)文件有read/write操作的時(shí)候。Buffer Cache則主要是設(shè)計(jì)用來(lái)在系統(tǒng)對(duì)塊設(shè)備進(jìn)行讀寫(xiě)的時(shí)候,對(duì)塊進(jìn)行數(shù)據(jù)緩存的系統(tǒng)來(lái)使用。
磁盤(pán)Cache有兩大功能:預(yù)讀和回寫(xiě)。預(yù)讀其實(shí)就是利用了局部性原理,具體過(guò)程是:對(duì)于每個(gè)文件的第一個(gè)讀請(qǐng)求,系統(tǒng)讀入所請(qǐng)求的頁(yè)面并讀入緊隨其后的少數(shù)幾個(gè)頁(yè)面(通常是三個(gè)頁(yè)面),這時(shí)的預(yù)讀稱(chēng)為同步預(yù)讀。對(duì)于第二次讀請(qǐng)求,如果所讀頁(yè)面不在Cache中,即不在前次預(yù)讀的頁(yè)中,則表明文件訪(fǎng)問(wèn)不是順序訪(fǎng)問(wèn),系統(tǒng)繼續(xù)采用同步預(yù)讀;如果所讀頁(yè)面在Cache中,則表明前次預(yù)讀命中,操作系統(tǒng)把預(yù)讀頁(yè)的大小擴(kuò)大一倍,此時(shí)預(yù)讀過(guò)程是異步的,應(yīng)用程序可以不等預(yù)讀完成即可返回,只要后臺(tái)慢慢讀頁(yè)面即可,這時(shí)的預(yù)讀稱(chēng)為異步預(yù)讀。任何接下來(lái)的讀請(qǐng)求都會(huì)處于兩種情況之一:第一種情況是所請(qǐng)求的頁(yè)面處于預(yù)讀的頁(yè)面中,這時(shí)繼續(xù)進(jìn)行異步預(yù)讀;第二種情況是所請(qǐng)求的頁(yè)面處于預(yù)讀頁(yè)面之外,這時(shí)系統(tǒng)就要進(jìn)行同步預(yù)讀。
回寫(xiě)是通過(guò)暫時(shí)將數(shù)據(jù)存在Cache里,然后統(tǒng)一異步寫(xiě)到磁盤(pán)中。通過(guò)這種異步的數(shù)據(jù)I/O模式解決了程序中的計(jì)算速度和數(shù)據(jù)存儲(chǔ)速度不匹配的鴻溝,減少了訪(fǎng)問(wèn)底層存儲(chǔ)介質(zhì)的次數(shù),使存儲(chǔ)系統(tǒng)的性能大大提高。Linux 2.6.32內(nèi)核之前,采用pdflush機(jī)制來(lái)將臟頁(yè)真正寫(xiě)到磁盤(pán)中,什么時(shí)候開(kāi)始回寫(xiě)呢?下面兩種情況下,臟頁(yè)會(huì)被寫(xiě)回到磁盤(pán):
回寫(xiě)開(kāi)始后,pdflush會(huì)持續(xù)寫(xiě)數(shù)據(jù),直到滿(mǎn)足以下兩個(gè)條件:
Linux 2.6.32內(nèi)核之后,放棄了原有的pdflush機(jī)制,改成了bdi_writeback機(jī)制。bdi_writeback機(jī)制主要解決了原有fdflush機(jī)制存在的一個(gè)問(wèn)題:在多磁盤(pán)的系統(tǒng)中,pdflush管理了所有磁盤(pán)的Cache,從而導(dǎo)致一定程度的I/O瓶頸。bdi_writeback機(jī)制為每個(gè)磁盤(pán)都創(chuàng)建了一個(gè)線(xiàn)程,專(zhuān)門(mén)負(fù)責(zé)這個(gè)磁盤(pán)的Page Cache的刷新工作,從而實(shí)現(xiàn)了每個(gè)磁盤(pán)的數(shù)據(jù)刷新在線(xiàn)程級(jí)的分離,提高了I/O性能。
回寫(xiě)機(jī)制存在的問(wèn)題是回寫(xiě)不及時(shí)引發(fā)數(shù)據(jù)丟失(可由sync|fsync解決),回寫(xiě)期間讀I/O性能很差。
通用塊層
通用塊層的主要工作是:接收上層發(fā)出的磁盤(pán)請(qǐng)求,并最終發(fā)出I/O請(qǐng)求。該層隱藏了底層硬件塊設(shè)備的特性,為塊設(shè)備提供了一個(gè)通用的抽象視圖。
對(duì)于VFS和具體的文件系統(tǒng)來(lái)說(shuō),塊(Block)是基本的數(shù)據(jù)傳輸單元,當(dāng)內(nèi)核訪(fǎng)問(wèn)文件的數(shù)據(jù)時(shí),它首先從磁盤(pán)上讀取一個(gè)塊。但是對(duì)于磁盤(pán)來(lái)說(shuō),扇區(qū)是最小的可尋址單元,塊設(shè)備無(wú)法對(duì)比它還小的單元進(jìn)行尋址和操作。由于扇區(qū)是磁盤(pán)的最小可尋址單元,所以塊不能比扇區(qū)還小,只能整數(shù)倍于扇區(qū)大小,即一個(gè)塊對(duì)應(yīng)磁盤(pán)上的一個(gè)或多個(gè)扇區(qū)。一般來(lái)說(shuō),塊大小是2的整數(shù)倍,而且由于Page Cache層的最小單元是頁(yè)(Page),所以塊大小不能超過(guò)一頁(yè)的長(zhǎng)度。
大多情況下,數(shù)據(jù)的傳輸通過(guò)DMA方式。舊的磁盤(pán)控制器,僅僅支持簡(jiǎn)單的DMA操作:每次數(shù)據(jù)傳輸,只能傳輸磁盤(pán)上相鄰的扇區(qū),即數(shù)據(jù)在內(nèi)存中也是連續(xù)的。這是因?yàn)槿绻麄鬏敺沁B續(xù)的扇區(qū),會(huì)導(dǎo)致磁盤(pán)花費(fèi)更多的時(shí)間在尋址操作上。而現(xiàn)在的磁盤(pán)控制器支持“分散/聚合”DMA操作,這種模式下,數(shù)據(jù)傳輸可以在多個(gè)非連續(xù)的內(nèi)存區(qū)域中進(jìn)行。為了利用“分散/聚合”DMA操作,塊設(shè)備驅(qū)動(dòng)必須能處理被稱(chēng)為段(segments)的數(shù)據(jù)單元。一個(gè)段就是一個(gè)內(nèi)存頁(yè)面或一個(gè)頁(yè)面的部分,它包含磁盤(pán)上相鄰扇區(qū)的數(shù)據(jù)。
通用塊層是粘合所有上層和底層的部分,一個(gè)頁(yè)的磁盤(pán)數(shù)據(jù)布局如下圖所示:
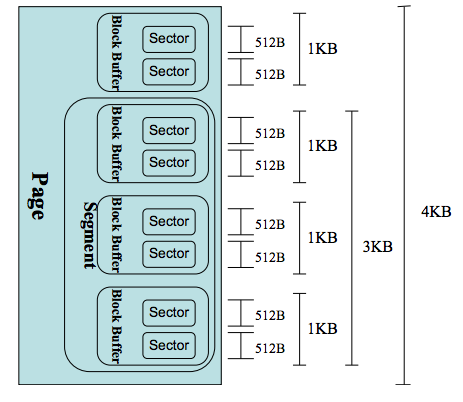
I/O調(diào)度層
I/O調(diào)度層的功能是管理塊設(shè)備的請(qǐng)求隊(duì)列。即接收通用塊層發(fā)出的I/O請(qǐng)求,緩存請(qǐng)求并試圖合并相鄰的請(qǐng)求。并根據(jù)設(shè)置好的調(diào)度算法,回調(diào)驅(qū)動(dòng)層提供的請(qǐng)求處理函數(shù),以處理具體的I/O請(qǐng)求。
如果簡(jiǎn)單地以?xún)?nèi)核產(chǎn)生請(qǐng)求的次序直接將請(qǐng)求發(fā)給塊設(shè)備的話(huà),那么塊設(shè)備性能肯定讓人難以接受,因?yàn)榇疟P(pán)尋址是整個(gè)計(jì)算機(jī)中最慢的操作之一。為了優(yōu)化尋址操作,內(nèi)核不會(huì)一旦接收到I/O請(qǐng)求后,就按照請(qǐng)求的次序發(fā)起塊I/O請(qǐng)求。為此Linux實(shí)現(xiàn)了幾種I/O調(diào)度算法,算法基本思想就是通過(guò)合并和排序I/O請(qǐng)求隊(duì)列中的請(qǐng)求,以此大大降低所需的磁盤(pán)尋道時(shí)間,從而提高整體I/O性能。
常見(jiàn)的I/O調(diào)度算法包括Noop調(diào)度算法(No Operation)、CFQ(完全公正排隊(duì)I/O調(diào)度算法)、DeadLine(截止時(shí)間調(diào)度算法)、AS預(yù)測(cè)調(diào)度算法等。
Noop算法:最簡(jiǎn)單的I/O調(diào)度算法。該算法僅適當(dāng)合并用戶(hù)請(qǐng)求,并不排序請(qǐng)求。新的請(qǐng)求通常被插在調(diào)度隊(duì)列的開(kāi)頭或末尾,下一個(gè)要處理的請(qǐng)求總是隊(duì)列中的第一個(gè)請(qǐng)求。這種算法是為不需要尋道的塊設(shè)備設(shè)計(jì)的,如SSD。因?yàn)槠渌齻€(gè)算法的優(yōu)化是基于縮短尋道時(shí)間的,而SSD硬盤(pán)沒(méi)有所謂的尋道時(shí)間且I/O響應(yīng)時(shí)間非常短。
CFQ算法:算法的主要目標(biāo)是在觸發(fā)I/O請(qǐng)求的所有進(jìn)程中確保磁盤(pán)I/O帶寬的公平分配。算法使用許多個(gè)排序隊(duì)列,存放了不同進(jìn)程發(fā)出的請(qǐng)求。通過(guò)散列將同一個(gè)進(jìn)程發(fā)出的請(qǐng)求插入同一個(gè)隊(duì)列中。采用輪詢(xún)方式掃描隊(duì)列,從第一個(gè)非空隊(duì)列開(kāi)始,依次調(diào)度不同隊(duì)列中特定個(gè)數(shù)(公平)的請(qǐng)求,然后將這些請(qǐng)求移動(dòng)到調(diào)度隊(duì)列的末尾。
Deadline算法:算法引入了兩個(gè)排隊(duì)隊(duì)列分別包含讀請(qǐng)求和寫(xiě)請(qǐng)求,兩個(gè)最后期限隊(duì)列包含相同的讀和寫(xiě)請(qǐng)求。本質(zhì)就是一個(gè)超時(shí)定時(shí)器,當(dāng)請(qǐng)求被傳給電梯算法時(shí)開(kāi)始計(jì)時(shí)。一旦最后期限隊(duì)列中的超時(shí)時(shí)間已到,就想請(qǐng)求移至調(diào)度隊(duì)列末尾。Deadline算法避免了電梯調(diào)度策略(為了減少尋道時(shí)間,會(huì)優(yōu)先處理與上一個(gè)請(qǐng)求相近的請(qǐng)求)帶來(lái)的對(duì)某個(gè)請(qǐng)求忽略很長(zhǎng)一段時(shí)間的可能。
AS算法:AS算法本質(zhì)上依據(jù)局部性原理,預(yù)測(cè)進(jìn)程發(fā)出的讀請(qǐng)求與剛被調(diào)度的請(qǐng)求在磁盤(pán)上可能是“近鄰”。算法統(tǒng)計(jì)每個(gè)進(jìn)程I/O操作信息,當(dāng)剛剛調(diào)度了由某個(gè)進(jìn)程的一個(gè)讀請(qǐng)求之后,算法馬上檢查排序隊(duì)列中的下一個(gè)請(qǐng)求是否來(lái)自同一個(gè)進(jìn)程。如果是,立即調(diào)度下一個(gè)請(qǐng)求。否則,查看關(guān)于該進(jìn)程的統(tǒng)計(jì)信息,如果確定進(jìn)程p可能很快發(fā)出另一個(gè)讀請(qǐng)求,那么就延遲一小段時(shí)間。
前文中計(jì)算出的IOPS是理論上的隨機(jī)讀寫(xiě)的最大IOPS,在隨機(jī)讀寫(xiě)中,每次I/O操作的尋址和旋轉(zhuǎn)延時(shí)都不能忽略不計(jì),有了這兩個(gè)時(shí)間的存在也就限制了IOPS的大小。現(xiàn)在如果我們考慮在讀取一個(gè)很大的存儲(chǔ)連續(xù)分布在磁盤(pán)的文件,因?yàn)槲募拇鎯?chǔ)的分布是連續(xù)的,磁頭在完成一個(gè)讀I/O操作之后,不需要重新尋址,也不需要旋轉(zhuǎn)延時(shí),在這種情況下我們能到一個(gè)很大的IOPS值。這時(shí)由于不再考慮尋址和旋轉(zhuǎn)延時(shí),則性能瓶頸僅是數(shù)據(jù)傳輸時(shí)延,假設(shè)數(shù)據(jù)傳輸時(shí)延為0.4ms,那么IOPS=1000 / 0.4 = 2500 IOPS。
在許多的開(kāi)源框架如Kafka、HBase中,都通過(guò)追加寫(xiě)的方式來(lái)盡可能的將隨機(jī)I/O轉(zhuǎn)換為順序I/O,以此來(lái)降低尋址時(shí)間和旋轉(zhuǎn)延時(shí),從而最大限度的提高IOPS。
塊設(shè)備驅(qū)動(dòng)層
驅(qū)動(dòng)層中的驅(qū)動(dòng)程序?qū)?yīng)具體的物理塊設(shè)備。它從上層中取出I/O請(qǐng)求,并根據(jù)該I/O請(qǐng)求中指定的信息,通過(guò)向具體塊設(shè)備的設(shè)備控制器發(fā)送命令的方式,來(lái)操縱設(shè)備傳輸數(shù)據(jù)。這里不再贅述。
在上一節(jié)中我們了解了Linux系統(tǒng)中請(qǐng)求到達(dá)磁盤(pán)的一次完整過(guò)程,期間Linux通過(guò)Cache以及排序合并I/O請(qǐng)求來(lái)提高系統(tǒng)的性能。其本質(zhì)就是由于磁盤(pán)隨機(jī)讀寫(xiě)慢、順序讀寫(xiě)快。本節(jié)針對(duì)常見(jiàn)開(kāi)源系統(tǒng)闡述一些基于磁盤(pán)I/O特性的設(shè)計(jì)技巧。
采用追加寫(xiě)
在進(jìn)行系統(tǒng)設(shè)計(jì)時(shí),良好的讀性能和寫(xiě)性能往往不可兼得。在許多常見(jiàn)的開(kāi)源系統(tǒng)中都是優(yōu)先在保證寫(xiě)性能的前提下來(lái)優(yōu)化讀性能。那么如何設(shè)計(jì)能讓一個(gè)系統(tǒng)擁有良好的寫(xiě)性能呢?一個(gè)好的辦法就是采用追加寫(xiě),每次將數(shù)據(jù)添加到文件。由于完全是順序的,所以可以具有非常好的寫(xiě)操作性能。但是這種方式也存在一些缺點(diǎn):從文件中讀一些數(shù)據(jù)時(shí)將會(huì)需要更多的時(shí)間:需要倒序掃描,直到找到所需要的內(nèi)容。當(dāng)然在一些簡(jiǎn)單的場(chǎng)景下也能夠保證讀操作的性能:
數(shù)據(jù)是被整體訪(fǎng)問(wèn),比如HDFS
- HDFS建立在一次寫(xiě)多次讀的模型之上。在HDFS中就是采用了追加寫(xiě)并且設(shè)計(jì)為高數(shù)據(jù)吞吐量;高吞吐量必然以高延遲為代價(jià),所以HDFS并不適用于對(duì)數(shù)據(jù)訪(fǎng)問(wèn)要求低延遲的場(chǎng)景;由于采用是的追加寫(xiě),也并不適用于任意修改文件的場(chǎng)景。HDFS設(shè)計(jì)為流式訪(fǎng)問(wèn)大文件,使用大數(shù)據(jù)塊并且采用流式數(shù)據(jù)訪(fǎng)問(wèn)來(lái)保證數(shù)據(jù)被整體訪(fǎng)問(wèn),同時(shí)最小化硬盤(pán)的尋址開(kāi)銷(xiāo),只需要一次尋址即可,這時(shí)尋址時(shí)間相比于傳輸時(shí)延可忽略,從而也擁有良好的讀性能。HDFS不適合存儲(chǔ)小文件,原因之一是由于NameNode內(nèi)存不足問(wèn)題,還有就是因?yàn)樵L(fǎng)問(wèn)大量小文件需要執(zhí)行大量的尋址操作,并且需要不斷的從一個(gè)datanode跳到另一個(gè)datanode,這樣會(huì)大大降低數(shù)據(jù)訪(fǎng)問(wèn)性能。
知道文件明確的偏移量,比如Kafka
- 在Kafka中,采用消息追加的方式來(lái)寫(xiě)入每個(gè)消息,每個(gè)消息讀寫(xiě)時(shí)都會(huì)利用Page Cache的預(yù)讀和后寫(xiě)特性,同時(shí)partition中都使用順序讀寫(xiě),以此來(lái)提高I/O性能。雖然Kafka能夠根據(jù)偏移量查找到具體的某個(gè)消息,但是查找過(guò)程是順序查找,因此如果數(shù)據(jù)很大的話(huà),查找效率就很低。所以Kafka中采用了分段和索引的方式來(lái)解決查找效率問(wèn)題。Kafka把一個(gè)patition大文件又分成了多個(gè)小文件段,每個(gè)小文件段以偏移量命名,通過(guò)多個(gè)小文件段,不僅可以使用二分搜索法很快定位消息,同時(shí)也容易定期清除或刪除已經(jīng)消費(fèi)完的文件,減少磁盤(pán)占用。為了進(jìn)一步提高查找效率,Kafka為每個(gè)分段后的數(shù)據(jù)建立了索引文件,并通過(guò)索引文件稀疏存儲(chǔ)來(lái)降低元數(shù)據(jù)占用大小。一個(gè)段中數(shù)據(jù)對(duì)應(yīng)結(jié)構(gòu)如下圖所示:

在面對(duì)更復(fù)雜的讀場(chǎng)景(比如按key)時(shí),如何來(lái)保證讀操作的性能呢?簡(jiǎn)單的方式是像Kafka那樣,將文件數(shù)據(jù)有序保存,使用二分查找來(lái)優(yōu)化效率;或者通過(guò)建索引的方式來(lái)進(jìn)行優(yōu)化;也可以采用hash的方式將數(shù)據(jù)分割為不同的桶。以上的方法都能增加讀操作的性能,但是由于在數(shù)據(jù)上強(qiáng)加了數(shù)據(jù)結(jié)構(gòu),又會(huì)降低寫(xiě)操作的性能。比如如果采用索引的方式來(lái)優(yōu)化讀操作,那么在更新索引時(shí)就需要更新B-tree中的特定部分,這時(shí)候的寫(xiě)操作就是隨機(jī)寫(xiě)。那么有沒(méi)有一種辦法在保證寫(xiě)性能不損失的同時(shí)也提供較好的讀性能呢?一個(gè)好的選擇就是使用LSM-tree。LSM-tree與B-tree相比,LSM-tree犧牲了部分讀操作,以此大幅提高寫(xiě)性能。
- 日志結(jié)構(gòu)的合并樹(shù)LSM(The Log-Structured Merge-Tree)是HBase,LevelDB等NoSQL數(shù)據(jù)庫(kù)的存儲(chǔ)引擎。Log-Structured的思想是將整個(gè)磁盤(pán)看做一個(gè)日志,在日志中存放永久性數(shù)據(jù)及其索引,每次都添加到日志的末尾。并且通過(guò)將很多小文件的存取轉(zhuǎn)換為連續(xù)的大批量傳輸,使得對(duì)于文件系統(tǒng)的大多數(shù)存取都是順序的,從而提高磁盤(pán)I/O。LSM-tree就是這樣一種采用追加寫(xiě)、數(shù)據(jù)有序以及將隨機(jī)I/O轉(zhuǎn)換為順序I/O的延遲更新,批量寫(xiě)入硬盤(pán)的數(shù)據(jù)結(jié)構(gòu)。LSM-tree將數(shù)據(jù)的修改增量先保存在內(nèi)存中,達(dá)到指定的大小限制后再將這些修改操作批量寫(xiě)入磁盤(pán)。因此比較舊的文件不會(huì)被更新,重復(fù)的紀(jì)錄只會(huì)通過(guò)創(chuàng)建新的紀(jì)錄來(lái)覆蓋,這也就產(chǎn)生了一些冗余的數(shù)據(jù)。所以系統(tǒng)會(huì)周期性的合并一些數(shù)據(jù),移除重復(fù)的更新或者刪除紀(jì)錄,同時(shí)也會(huì)刪除上述的冗余。在進(jìn)行讀操作時(shí),如果內(nèi)存中沒(méi)有找到相應(yīng)的key,那么就是倒序從一個(gè)個(gè)磁盤(pán)文件中查找。如果文件越來(lái)越多那么讀性能就會(huì)越來(lái)越低,目前的解決方案是采用頁(yè)緩存來(lái)減少查詢(xún)次數(shù),周期合并文件也有助于提高讀性能。在文件越來(lái)越多時(shí),可通過(guò)布隆過(guò)濾器來(lái)避免大量的讀文件操作。LSM-tree犧牲了部分讀性能,以此來(lái)?yè)Q取寫(xiě)入的最大化性能,特別適用于讀需求低,會(huì)產(chǎn)生大量插入操作的應(yīng)用環(huán)境。
文件合并和元數(shù)據(jù)優(yōu)化
目前的大多數(shù)文件系統(tǒng),如XFS/Ext4、GFS、HDFS,在元數(shù)據(jù)管理、緩存管理等實(shí)現(xiàn)策略上都側(cè)重大文件。上述基于磁盤(pán)I/O特性設(shè)計(jì)的系統(tǒng)都有一個(gè)共性特點(diǎn)就是都運(yùn)行在這些文件系統(tǒng)之上。這些文件系統(tǒng)在面臨海量時(shí)在性能和存儲(chǔ)效率方面都大幅降低,本節(jié)來(lái)探討下海量小文件下的系統(tǒng)設(shè)計(jì)。
常見(jiàn)文件系統(tǒng)在海量小文件應(yīng)用下性能表現(xiàn)不佳的根本原因是磁盤(pán)最適合順序的大文件I/O讀寫(xiě)模式,而非常不適合隨機(jī)的小文件I/O讀寫(xiě)模式。主要原因體現(xiàn)在元數(shù)據(jù)管理低效和數(shù)據(jù)布局低效:
元數(shù)據(jù)管理低效:由于小文件數(shù)據(jù)內(nèi)容較少,因此元數(shù)據(jù)的訪(fǎng)問(wèn)性能對(duì)小文件訪(fǎng)問(wèn)性能影響巨大。Ext2文件系統(tǒng)中Inode和Data Block分別保存在不同的物理位置上,一次讀操作需要至少經(jīng)過(guò)兩次的獨(dú)立訪(fǎng)問(wèn)。在海量小文件應(yīng)用下,Inode的頻繁訪(fǎng)問(wèn),使得原本的并發(fā)訪(fǎng)問(wèn)轉(zhuǎn)變?yōu)榱撕A康碾S機(jī)訪(fǎng)問(wèn),大大降低了性能。另外,大量的小文件會(huì)快速耗盡Inode資源,導(dǎo)致磁盤(pán)盡管有大量Data Block剩余也無(wú)法存儲(chǔ)文件,會(huì)浪費(fèi)磁盤(pán)空間。
數(shù)據(jù)布局低效:Ext2在Inode中使用多級(jí)指針來(lái)索引數(shù)據(jù)塊。對(duì)于大文件,數(shù)據(jù)塊的分配會(huì)盡量連續(xù),這樣會(huì)具有比較好的空間局部性。但是對(duì)于小文件,數(shù)據(jù)塊可能零散分布在磁盤(pán)上的不同位置,并且會(huì)造成大量的磁盤(pán)碎片,不僅造成訪(fǎng)問(wèn)性能下降,還大量浪費(fèi)了磁盤(pán)空間。數(shù)據(jù)塊一般為1KB、2KB或4KB,對(duì)于小于4KB的小文件,Inode與數(shù)據(jù)的分開(kāi)存儲(chǔ)破壞了空間局部性,同時(shí)也造成了大量的隨機(jī)I/O。
對(duì)于海量小文件應(yīng)用,常見(jiàn)的I/O流程復(fù)雜也是造成磁盤(pán)性能不佳的原因。對(duì)于小文件,磁盤(pán)的讀寫(xiě)所占用的時(shí)間較少,而用于文件的open()操作占用了絕大部分系統(tǒng)時(shí)間,導(dǎo)致磁盤(pán)有效服務(wù)時(shí)間非常低,磁盤(pán)性能低下。針對(duì)于問(wèn)題的根源,優(yōu)化的思路大體上分為:
小文件合并 小文件合并為大文件后,首先減少了大量元數(shù)據(jù),提高了元數(shù)據(jù)的檢索和查詢(xún)效率,降低了文件讀寫(xiě)的I/O操作延時(shí)。其次將可能連續(xù)訪(fǎng)問(wèn)的小文件一同合并存儲(chǔ),增加了文件之間的局部性,將原本小文件間的隨機(jī)訪(fǎng)問(wèn)變?yōu)榱隧樞蛟L(fǎng)問(wèn),大大提高了性能。同時(shí),合并存儲(chǔ)能夠有效的減少小文件存儲(chǔ)時(shí)所產(chǎn)生的磁盤(pán)碎片問(wèn)題,提高了磁盤(pán)的利用率。最后,合并之后小文件的訪(fǎng)問(wèn)流程也有了很大的變化,由原來(lái)許多的open操作轉(zhuǎn)變?yōu)榱藄eek操作,定位到大文件具體的位置即可。如何尋址這個(gè)大文件中的小文件呢?其實(shí)就是利用一個(gè)旁路數(shù)據(jù)庫(kù)來(lái)記錄每個(gè)小文件在這個(gè)大文件中的偏移量和長(zhǎng)度等信息。其實(shí)小文件合并的策略本質(zhì)上就是通過(guò)分層的思想來(lái)存儲(chǔ)元數(shù)據(jù)。中控節(jié)點(diǎn)存儲(chǔ)一級(jí)元數(shù)據(jù),也就是大文件與底層塊的對(duì)應(yīng)關(guān)系;數(shù)據(jù)節(jié)點(diǎn)存放二級(jí)元數(shù)據(jù),也就是最終的用戶(hù)文件在這些一級(jí)大塊中的存儲(chǔ)位置對(duì)應(yīng)關(guān)系,經(jīng)過(guò)兩級(jí)尋址來(lái)讀寫(xiě)數(shù)據(jù)。
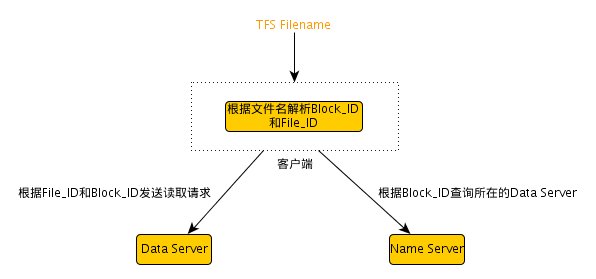
- 淘寶的TFS就采用了小文件合并存儲(chǔ)的策略。TFS中默認(rèn)Block大小為64M,每個(gè)塊中會(huì)存儲(chǔ)許多不同的小文件,但是這個(gè)塊只占用一個(gè)Inode。假設(shè)一個(gè)Block為64M,數(shù)量級(jí)為1PB。那么NameServer上會(huì)有 1 * 1024 * 1024 * 1024 / 64 = 16.7M個(gè)Block。假設(shè)每個(gè)Block的元數(shù)據(jù)大小為0.1K,則占用內(nèi)存不到2G。在TFS中,文件名中包含了Block ID和File ID,通過(guò)Block ID定位到具體的DataServer上,然后DataServer會(huì)根據(jù)本地記錄的信息來(lái)得到File ID所在Block的偏移量,從而讀取到正確的文件內(nèi)容。TFS一次讀過(guò)程如下圖所示:
元數(shù)據(jù)管理優(yōu)化 一般來(lái)說(shuō)元數(shù)據(jù)信息包括名稱(chēng)、文件大小、設(shè)備標(biāo)識(shí)符、用戶(hù)標(biāo)識(shí)符、用戶(hù)組標(biāo)識(shí)符等等,在小文件系統(tǒng)中可以對(duì)元數(shù)據(jù)信息進(jìn)行精簡(jiǎn),僅保存足夠的信息即可。元數(shù)據(jù)精簡(jiǎn)可以減少元數(shù)據(jù)通信延時(shí),同時(shí)相同容量的Cache能存儲(chǔ)更多的元數(shù)據(jù),從而提高元數(shù)據(jù)使用效率。另外可以在文件名中就包含元數(shù)據(jù)信息,從而減少一個(gè)元數(shù)據(jù)的查詢(xún)操作。最后針對(duì)特別小的一些文件,可以采取元數(shù)據(jù)和數(shù)據(jù)并存的策略,將數(shù)據(jù)直接存儲(chǔ)在元數(shù)據(jù)之中,通過(guò)減少一次尋址操作從而大大提高性能。
- TFS中文件命名就隱含了位置信息等部分元數(shù)據(jù),從而減少了一個(gè)元數(shù)據(jù)的查詢(xún)操作。在Rerserfs中,對(duì)于小于1KB的小文件,Rerserfs可以將數(shù)據(jù)直接存儲(chǔ)在Inode中。
本文從磁盤(pán)性能指標(biāo)出發(fā),探究了操作系統(tǒng)與磁盤(pán)的交互以及對(duì)磁盤(pán)讀寫(xiě)的優(yōu)化,最后列舉了一些常用開(kāi)源系統(tǒng)中基于磁盤(pán)I/O特性的設(shè)計(jì)特點(diǎn)。期望通過(guò)展現(xiàn)磁盤(pán)I/O的特性,為存儲(chǔ)系統(tǒng)設(shè)計(jì)和解決一些系統(tǒng)性能問(wèn)題提供一種新思路。
喻梟,2016年加入美團(tuán),就職于美團(tuán)酒店旅游事業(yè)群境內(nèi)度假研發(fā)組。專(zhuān)注Java后臺(tái)開(kāi)發(fā),對(duì)并發(fā)編程和大數(shù)據(jù)有濃厚興趣。
最后發(fā)個(gè)廣告,美團(tuán)酒旅事業(yè)群境內(nèi)度假研發(fā)組長(zhǎng)期招聘Java后臺(tái)、架構(gòu)方面的人才,有興趣的同學(xué)可以發(fā)送簡(jiǎn)歷到j(luò)inmengzhe#meituan.com。
總結(jié)

- 上一篇: 机器学习从理论到工程的第二步-开发环境与
- 下一篇: Spring Cloud Stream如